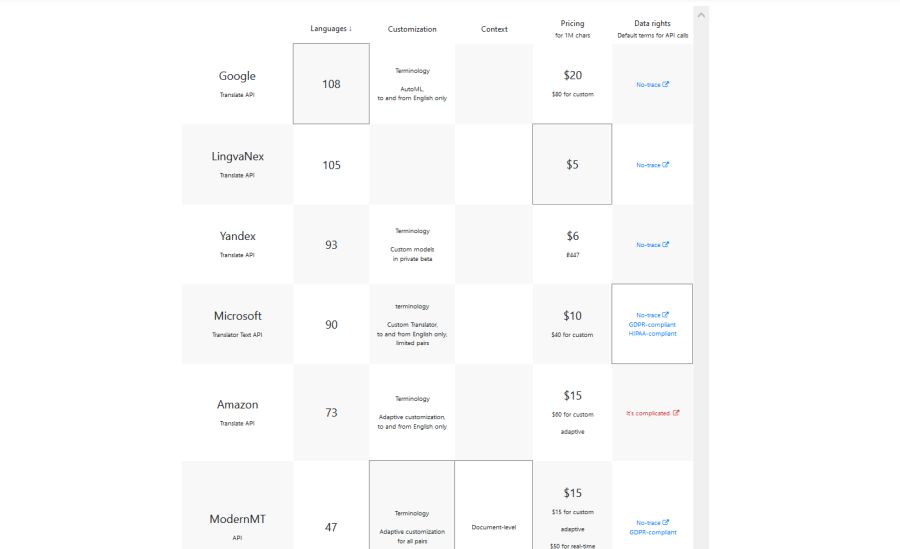
Kiedy MT jest posłuszne
Czego można spodziewać się po MT dotrenowanym pamięcią z dziedziny, w której pracujemy? A na ile MT może zaadaptować się do poprawek, jakie wprowadzamy poprawiając jego kolejne podpowiedzi?
Eksperyment z adaptującym się narzędziem do tłumaczenia maszynowego ModernMT został przeprowadzony przez Anonimową Tłumaczkę na platformie SDL Trados Studio 2017 w trzech fazach z wykorzystaniem tzw. tekstu „miękkiego” z obszaru nauk humanistycznych, w tłumaczeniu z języka polskiego na angielski:
- Faza 0 (ok. 18 tys. znaków ze spacjami) – podpięty silnik ModernMT bez żadnych dodatkowych zasobów.
- Faza 1 (ok. 22 tys. znaków ze spacjami) – podpięty silnik ModernMT z pamięcią bazującą na wcześniej przetłumaczonych tekstach dotyczących tej samej tematyki (ok. 500 tys. znaków ze spacjami), ustawioną do wykorzystania przez silnik MT, lecz bez aktualizacji.
- Faza 2 (ok. 60 tys. znaków ze spacjami) – podpięty silnik ModernMT z tą samą pamięcią, ustawioną do wykorzystania oraz aktualizacji przez silnik MT.
Faza 1 – silnik MT korzysta z pamięci
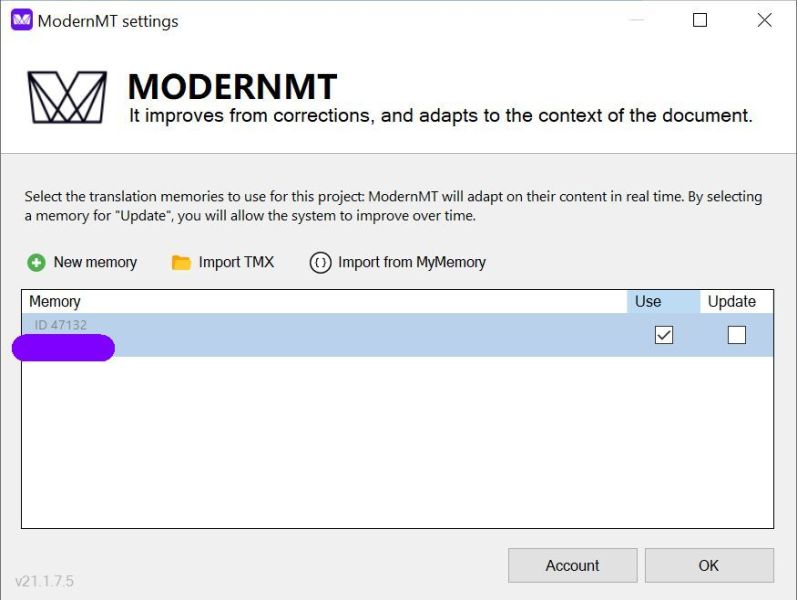
\W fazie 1 w stosunku do fazy 0 nastąpiła odczuwalna poprawa w zakresie doboru słownictwa. Klient miał określone wymagania co do nazewnictwa – faza 0 wymagała ze strony Tłumaczki w większości przypadków ręcznego wprowadzania poprawek, natomiast w fazie 1 silnik ModernMT dobierał właściwe określenia w ok. połowie przypadków.
Przykład terminologiczny (Faza 1):
Słowem często używanym w źródle było słowo panna. W fazie 0 silnik ModernMT tłumaczył to słowo na różne sposoby, przykładowo jako virgin czy maid, co Tłumaczka wielokrotnie zmieniała na maiden. Po zastosowaniu pamięci, w której występowała wyłącznie forma maiden, silnik ModernMT przeszedł na wersję maiden.
Przykład stylistyczny (Faza 1):
Ze społecznego punktu widzenia sprawa nie była jednak tak prosta i oczywista, zważywszy na stosunkowo późny wiek zawierania małżeństw.
MT: From a social point of view, however, the issue was not so simple and obvious, given the relatively late age of entering into marriages.
W fazie 0 tłumaczenie maszynowe bardzo często używanego w tekście źródłowym wyrażenia zawrzeć małżeństwo brzmiało conclude a marriage, co Tłumaczka wielokrotnie zmieniała na enter into a marriage/enter into marriages. Po zastosowaniu pamięci, w której występowała wyłącznie forma enter into a marriage/enter into marriages, silnik ModernMT zaczął dość konsekwentnie (aczkolwiek mniej konsekwentnie niż w fazie 2) używać sformułowania z enter into.
Faza 2 – silnik MT korzysta z pamięci i z poprawek
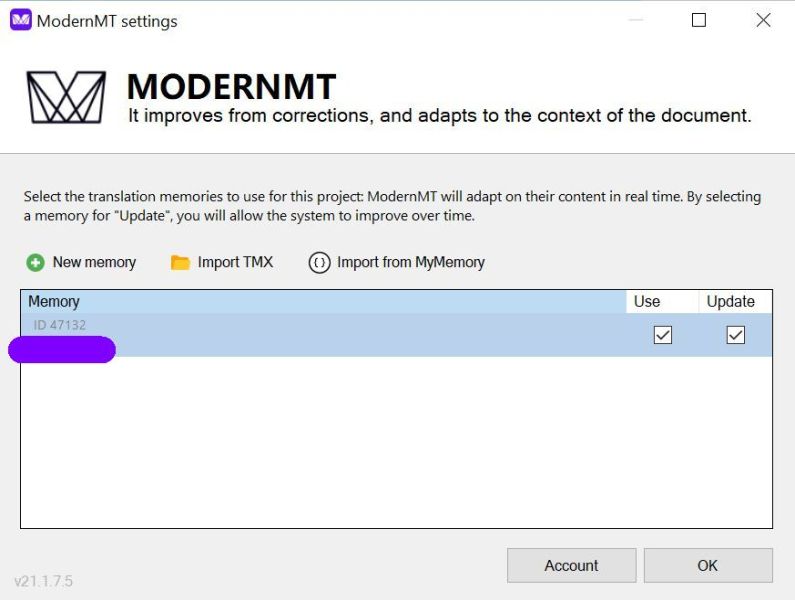
Poprawa stała się jeszcze bardziej dostrzegalna w fazie 2 – terminologia była właściwie dobierana w ponad połowie przypadków, poza tym tłumaczenie maszynowe zaczęło naśladować styl Tłumaczki, co przejawiało się w używaniu charakterystycznych wyrażeń, które Tłumaczka wcześniej wprowadzała ręcznie.
Przykład terminologiczny (Faza 2):
Jednym z wyrazów używanych w źródle było słowo testator, początkowo tłumaczone przez ModernMT jako tester (poprawne tłumaczenie to również testator). Po kilku (ok. 10) poprawkach ręcznych silnik ModernMT przeszedł na wersję tetator, a następnie już na poprawne tłumaczenie testator.
Przykład stylistyczny (Faza 2):
Charakter bazy nie pozwala jednak jednoznacznie określić ich udziału…
MT: However, the nature of the database does not make it possible to clearly determine their share…
Poprzednie tłumaczenie maszynowe nie pozwala brzmiało: does not allow for, co było przez Tłumaczkę konsekwentnie zmieniane na does not make it possible to. W fazie 2 silnik ModernMT „podchwycił” sformułowanie does not make it possible to.
Tłumaczenie maszynowe wymagało stałego nadzoru, ponieważ można było zaobserwować ewidentne „spadki formy” i powrót do poprawianych przez Tłumaczkę wersji. Można jednak z dużą dozą pewności stwierdzić, że w fazie 2 liczba zastosowanych form poprawnych wśród obserwowanych sformułowań przeważała nad liczbą form niepoprawnych.
Tłumaczka nie odnotowała zauważalnego zwiększenia szybkości tłumaczenia w kolejnych fazach (prawdopodobnie ze względu na charakter tekstu szybkość tłumaczenia utrzymywała się na stałym poziomie 9 tys. znaków ze spacjami na godzinę), jednak szczególnie w fazie 2 dało się dostrzec zwiększoną „lekkość” tłumaczenia – praca nad nim stała się wyraźnie łatwiejsza.
Warto zwrócić uwagę, że stała szybkość tłumaczenia odnosi się do wcześniejszej pracy z nietrenowanym MT (ModernMT, wcześniej DeepL), a nie do pracy bez żadnych podpowiedzi z MT.