A teraz szybko, zanim dotrze do nas, że to bez sensu!
Dwa popularne CAT-y reprezentują w tej chwili dwa różne podejścia do AI:
Trados dorobił się wtyczki OpenAI, która działa i konfiguruje się trochę inaczej niż znane już wtyczki MT. Jej niewątpliwą zaletą jest możliwość definiowania własnych zapytań (promptów), które pozwalają generować z ChatGPT tłumaczenia zwracające się do odbiorcy w liczbie pojedynczej, mnogiej albo neutralnie. Aby skorzystać z tej funkcji, trzeba mieć wykupiony dostęp do OpenAI i podać klucz API.
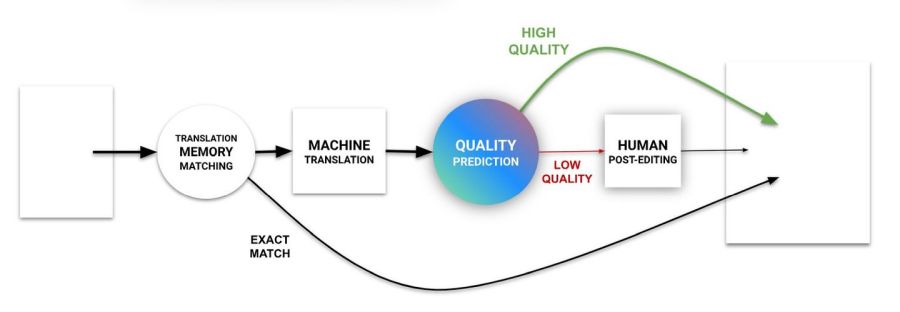
MemoQ wprowadził funkcję AIQE, czyli szacowanie jakości segmentów maszynowych (z dowolnej wtyczki MT) za pomocą dużego modelu językowego. Do wyboru jest TAUS albo ModelFront, do których również trzeba nabyć oddzielne klucze API.
Zaletą obu tych rozwiązań jest wprowadzenie najnowszych technologii językowych do CAT-ów. Wadą – ograniczenie przetwarzania do segmentu, czyli odcięcie jednej z największych zalet, jakie prezentują narzędzia AI oparte na dużych modelach językowych (LLM): potrafią one pracować na dokumencie jako całości, a w każdym razie na sporej jego części.
Ciekawe, kto z producentów CAT-ów pierwszy umożliwi pełniejsze wykorzystanie LLM do pracy na całym tekście, np. w takich zastosowaniach:
- wychwycenie kluczowej terminologii z tekstu źródłowego;
- sprawdzenie tekstu źródłowego i zaproponowanie poprawek (gramatyka, spójność, styl);
- przeredagowanie tekstu wynikowego w zadanym kierunku (formalny/nieformalny, zdania krótkie/długie);
- automatyczna kontrola jakości tłumaczenia według zadanych parametrów.
O części z tych zastosowań mówią praktycy z branży lokalizacyjnej na webinarze Intento “GPT in Localization“, wspominając też o możliwości generowania tekstu w wielu językach naraz – wszędzie tam, gdzie GPT potrafi wygenerować wystarczająco dobry tekst oryginalny (angielski), a surowe tłumaczenie maszynowe niekoniecznie spełnia wymagania jakościowe.
…Tyle że oczywiście nie da się ufać GPT w 100%, że czegoś nie nazmyśla 🙂