Co nowego u DeepLa
DeepL pozostaje jednym z najbardziej lubianych silników MT w parach z językiem polskim. Dlaczego i czy zawsze – tym zajmiemy się innym razem; dziś krótki przegląd nowości i rzeczy, na które warto zwrócić uwagę.
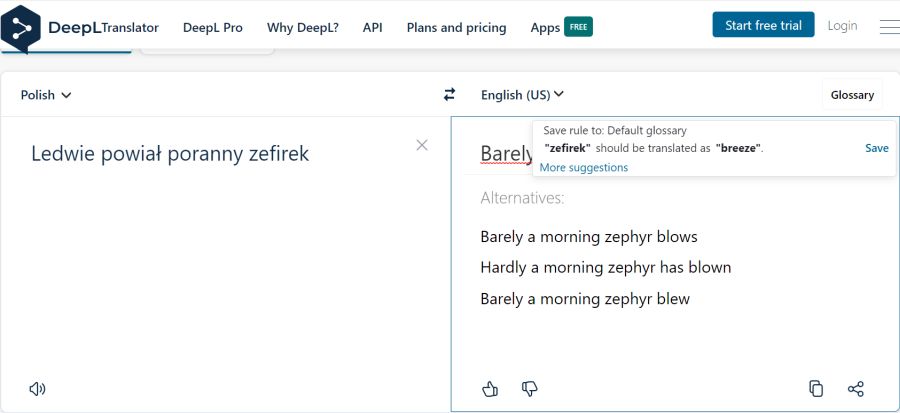
- Funkcja dodawania własnego glosariusza objęła niedawno język polski. Tłumacze, którzy ją już testują, donoszą, że DeepL nienajgorzej radzi sobie z przypadkami, rodzajami i liczbami.
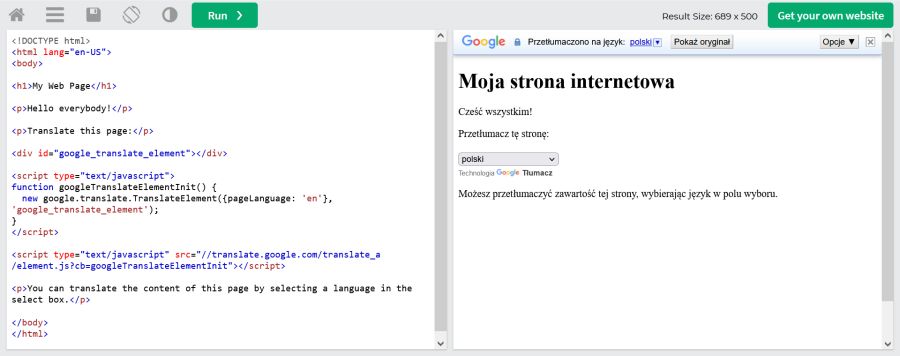
- DeepL z przeglądarki – tłumacząc fragmenty tekstu lub całe dokumenty – ewidentnie próbuje rozpoznawać kontekst: może nie w zakresie całego tekstu, ale akapitu lub kilku sąsiadujących zdań. Funkcja ta nie zadziała, póki co, poprzez API – czyli na przykład z narzędzia CAT, gdzie tekst tłumaczony jest segment po segmencie i maszyna nie ma szansy “zobaczyć” go szerzej. Niektórzy eksperymentują z segmentacją akapitami lub też z wysyłaniem do MT kilku segmentów naraz z pominięciem wtyczki.
- Skoro jesteśmy przy kontekście: DeepL, tak jak każdy inny silnik (oraz tłumacze profesjonalni), nie zdziała cudu przy bardzo krótkich segmentach, które mogą mieć wiele znaczeń. Jeśli tłumaczymy z przeglądarki i możemy zmieniać tekst źródłowy, to warto dodać kontekst, który ujednoznaczni tekst źródłowy. I tak na przykład “March” tłumaczony na angielski to “Marzec”, ale już “Long March” to “Długi Marsz”, a dla “March on” DeepL podaje tłumaczenia alternatywne i z marcem, i z marszem.
- Jeśli mamy tłumaczyć na język inny niż polski czy angielski, na przykład na czeski, a angielskim władamy dość dobrze, to tłumaczmy raczej z angielskiego na czeski niż z polskiego na czeski. Owszem, czeski i polski mają wiele wspólnego – niestety najprawdopodobniej DeepL będzie tłumaczyć polski > angielski > czeski, a to oznacza możliwość przekłamań na obu etapach. Wpisując oryginał w miarę poprawnie po angielsku, eliminujemy przynajmniej etap pierwszy.