Raport Intento 2022
Normally, we run multiple evaluations for our clients using various language pairs and domains, and observe different MT system rankings than those provided in this report
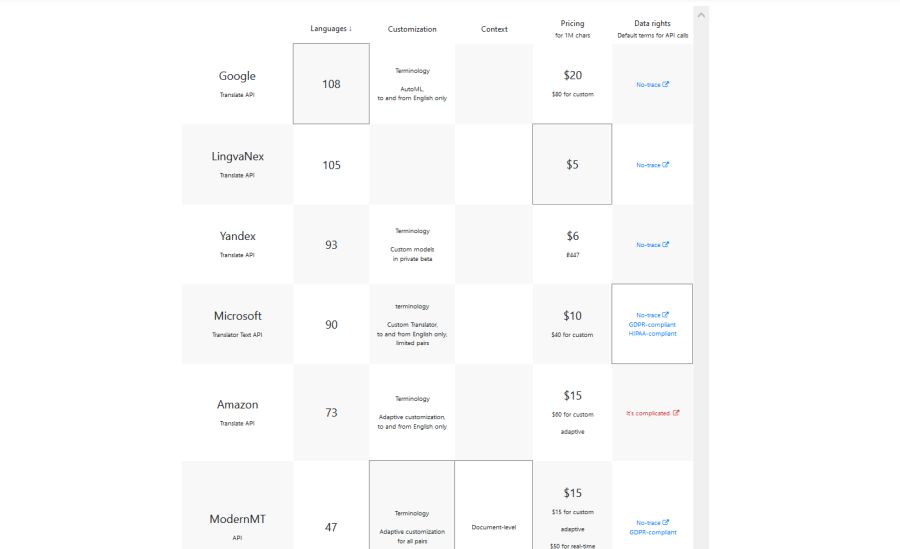
Firma Intento opublikowała właśnie tegoroczny raport z rynku MT, prezentujący stan z lipca 2022. Raport jest do pobrania bezpłatnie i przedstawia porównanie 31 silników dla 11 par językowych (polski się nie załapał, jest za to ukraiński) oraz 9 dziedzin, a do tego sporo informacji o trendach rynkowych (silniki tematyczne, pamięci/glosariusze, obsługa rzadszych języków). Można przy okazji poznać nieco metodologii – próbki tekstu liczą po 500 segmentów, a miarą automatyczną najlepiej skorelowaną z oceną człowieka okazuje się COMET. W przygotowaniu zasobów brała tym razem udział firma e2f.
Jeśli szukamy najlepszego silnika bez ustalonej dziedziny (tematyki) lub dla wielu różnych dziedzin, co bywa normalną praktyką np. w biurach tłumaczeń, to wyniki przedstawia załączony obrazek (DeepL i Google wygrywają). Jeśli działamy w konkretnej dziedzinie (takiej jak tłumaczenia prawne, medyczne lub literackie), to trzeba zagłębić się w raport nieco mocniej – biorąc również pod uwagę zastrzeżenie autorów raportu, że optymalne MT dla danego rodzaju tekstu i pary językowej może być jeszcze inne, niż wynika z raportu! Warto np. zauważyć, że cały raport opiera się na tłumaczeniu tekstu bez znaczników – jeśli mamy “na warsztacie” materiał, gdzie znaczniki są koniecznością (np. przy lokalizacji oprogramowania czy stron internetowych), to trzeba sprawdzić, jak dane MT sobie z nimi radzi.