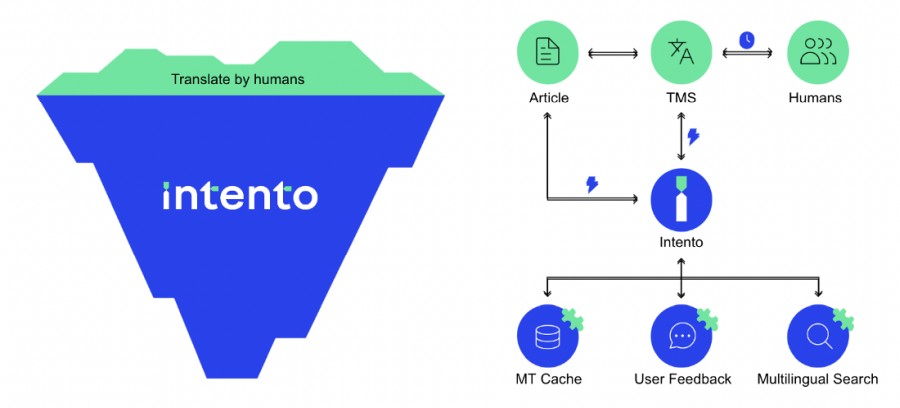
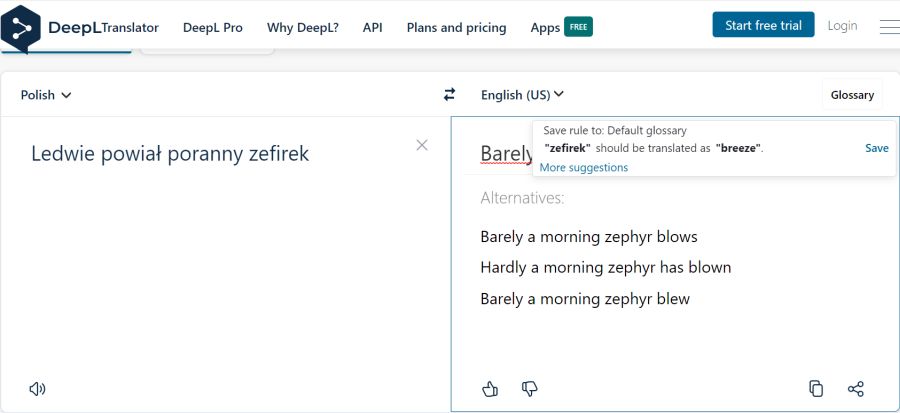
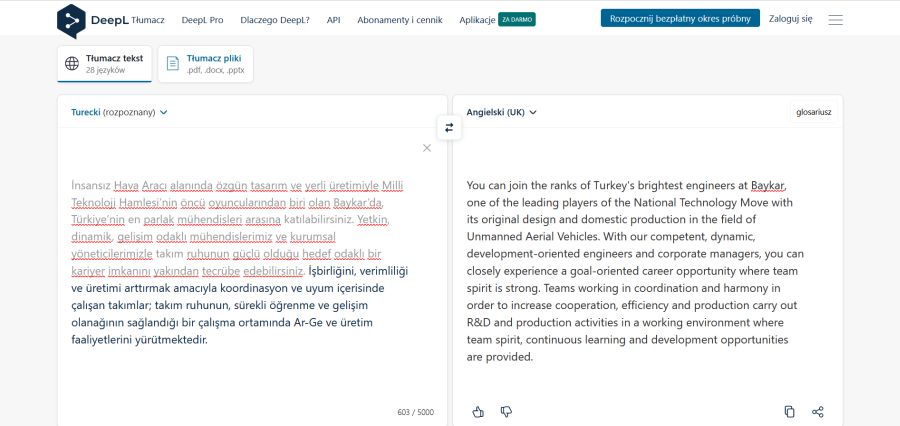
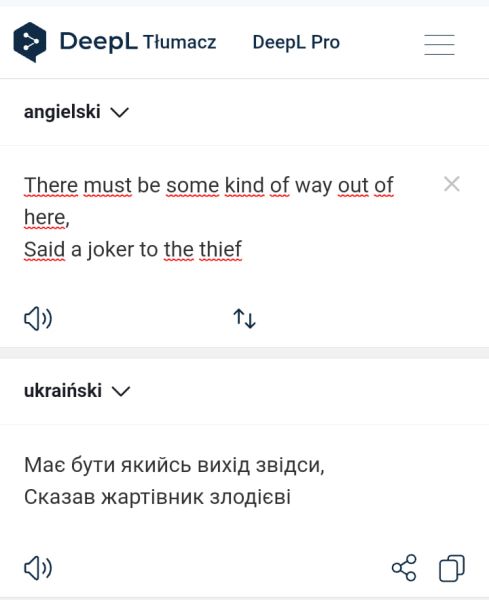
AI: skąd bierze, dokąd publikuje
Podczas gdy rozważania o roli generatywnego AI w dziejach świata wahają się od zachwytów po wieszczenie katastrofy (a gdzieś pośrodku jest postawa “meh, mielenie nudy”) – warto przyjrzeć się dwóm zagadnieniom:
- skąd brane są treści, na których trenowany jest dany model językowy – np. czy zawsze możemy licencjonować tekst, kod lub obraz, który AI dla nas wygenerowało?
- jak rozpoznać treści, które powstały przy użyciu generatywnego AI – np. kiedy jako konsument mamy gwarancję, że poprawność danego materiału została zweryfikowana przez człowieka?
Dwa podejścia do tych zagadnień proponują:
- Artificial Intelligence Act, projekt UE zmierzający do uregulowania m.in. powyższych aspektów AI;
- Foundation Model Transparency Index, badanie Uniwersytetu Stanforda, porównujące LLM-y wg kilkunastu elementów tego, co o nich wiadomo.