TAUS po raz trzeci – czyli kolejny raport o poprawianiu MT przez zastosowanie korpusów TAUS z wybranych dziedzin. Tym razem na scenę wkroczył Amazon (AWS) – i podszedł do sprawy bardzo poważnie, trenując wybrane silniki MT na korpusach TAUS z dziedziny sklepów internetowych, medyczno-farmaceutycznej i finansowej. W opublikowanym raporcie TAUS i Amazon pokazują wzrost jakości MT o średnio 15% wg miary BLEU. Wynik jest więc tylko nieznacznie gorszy od poprzednich prób wykonanych przez firmy Systran (+18%) i Pangeanic (+22%).
Współpraca TAUS i Amazona nie kończy się na raporcie:
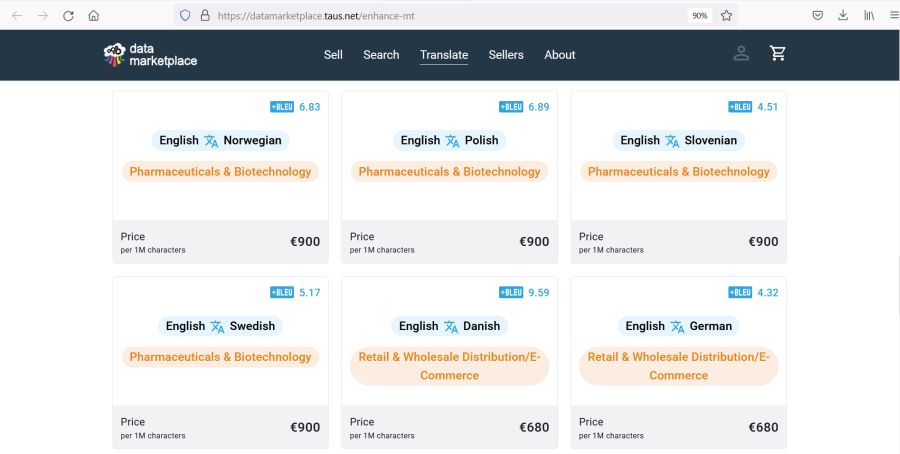
Amazon wprowadza do swojej oferty korpusy TAUS jako dane do treningu MT.
TAUS oferuje tematyczne silniki MT Amazona dla poszczególnych par językowych, podając spodziewaną poprawę jakości MT (BLEU) zgodnie z wynikami raportu.
Podobnie jak w poprzednich raportach, TAUS opiera ocenę MT wyłącznie na BLEU – nie podaje korelacji tej miary z wydajnością pracy postedytorów (co pozwalałoby wstępnie policzyć stawki za PE) ani z oceną odbiorców końcowych (co z kolei pomogłoby określić użyteczność trenowanego MT bez weryfikacji).
Nie chciałabym tu promować “lokalizacji” stron przez podłączenie Google Translate, ale jakby kolega pytał, to instrukcja trafiła do w3schools 😉 Powiedzcie też koledze, żeby przynajmniej sprawdził, czy inny silnik tłumaczeń maszynowch niż Google nie posłuży mu lepiej – na przykład DeepL, eTranslation, Tilde czy Yandex.
Firma Memsource zorganizowała 4-godzinne, bezpłatne szkolenie z efektywnego MTPE, stanowiące zarazem część projektu badawczego, jaki prowadzą Lucía Guerrero Romeo i Viveta Gene. Kilka aspektów szkolenia uznałabym za bardzo przydatne:
“Szkolenie stanowiskowe” uczestników – praktyczne ćwiczenia z postedycji MT w narzędziu CAT (Memsource).
Wskazanie technik i funkcji narzędzia CAT, które pomagają zwiększyć wydajność pracy postedytora; prawidłowe zastosowanie tych technik (np. odfiltrowanie i obrabianie oddzielnie segmentów z pamięci i segmentów z MT tylko wtedy, kiedy kontekst całego dokumentu nie jest istotny).
Przedstawienie typowych błędów MT, na które warto zwrócić uwagę.
Porównanie wydajności postedycji, wykonanej przez uczestników na próbkach, po “szkoleniu stanowiskowym”.
Dlaczego jednak uważam to szkolenie za nieco niepokojące?
Błędy krytyczne, gdzie MT zmienia sens tekstu, zostały wymienione po prostu jako jeden z typów błędów – gdzieś między nieuzgodnionym rodzajem a niepoprawną interpunkcją. Zabrakło wskazówek, jak te krytyczne błędy wychwytywać.
Za jedyne kryterium skuteczności “szkolenia stanowiskowego” – nota bene, spełnione – został uznany wzrost wydajności postedycji. Nie wiadomo, czy nie spadła przy tym jakość finalnego tłumaczenia.
Żeby podłączyć MT do narzędzia CAT, potrzebujemy klucza API. I tu rysują się dwa warianty:
Dostarczanie MT jest głównym zajęciem naszego dostawcy, więc dbanie o wygodę tłumaczy (i innych jednostek korzystających z MT przez API) ma u dostawcy wysoki priorytet. Tutaj pozyskanie klucza jest proste, by nie rzec – banalne. Do tej grupy należy na przykład DeepL czy ModernMT.
Dostarczanie MT jest jedną z wielu usług, jakie nasz dostawca świadczy w sieci, można wręcz nieraz domniemywać, że słupek “tłumaczenia maszynowe” ma u niego grubość linii na wykresie struktury przychodów. W tym przypadku pozyskanie klucza API jest trudne, bardzo trudne albo boleśnie upierdliwe. Do tej grupy zaliczyłabym Amazona (AWS), Microsoft (Bing) oraz Google.
Jak żyć? Naprzeciw tłumaczom w potrzebie wychodzi dokumentacja, jaką opracował Marcin Basiak w ramach projektu na studiach podyplomowych z komunikacji technicznej (Akademia Vistula). Polecam uwadze rozdział How to obtain API keys for MT plugins. Autor planuje aktualizacje treści, rozszerzenie o innych dostawców MT oraz zmiany strony formalnej dokumentu 🙂
Tilde i Hieronymus zaprezentowały system tłumaczeń maszynowych, który przetwarza dokumenty prawne w Szwajcarii. Wśród typowych wyzwań i rozwiązań, takich jak ochrona danych, ilość zasobów do treningu czy preferowana terminologia, znalazła się ciekawostka: długość zdań w tekstach prawnych. O ile w innych zastosowaniach przetwarzanie tekstów przed i po maszynie często obejmuje łączenie krótkich segmentów w logiczne całości, a potem ich rozdzielanie (tak dzieje się np. przy automatycznym tłumaczeniu napisów do filmów), o tyle dla tekstów prawnych wskazane okazało się raczej dzielenie zdań na mniejsze logiczne całości, bardziej strawne dla MT. Taka specyfika 🙂
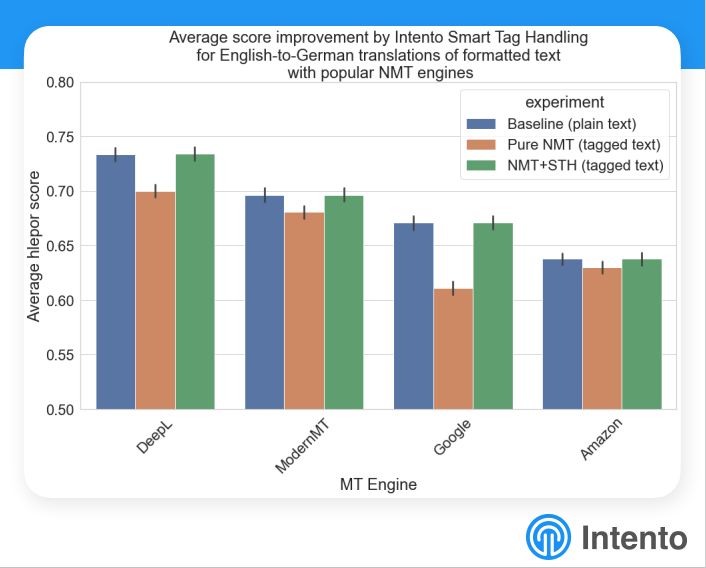
Intento reklamuje swoje rozwiązanie wspomagające tłumaczenie maszynowe treści, które nie są wolne od tagów. Rozwiązanie “Smart Tag Handling” jest zewnętrzne wględem silników MT – ma działać z dowolnym. Zostało przetestowane dla znaczników HTML (wyniki na załączonym wykresie) i dla tagów inline. Można by się tu więc spodziewać rozwiązania celowanego w lokalizację oprogramowania, tymczasem pierwszym rynkiem docelowym ma być maszynowe wspomaganie tłumaczenia napisów do filmów!
STH wygląda na warte sprawdzenia dla firm, które mają do tłumaczenia sporo mocno otagowanych treści i które borykają się z tym problemem, że silnik MT, który najlepiej radzi sobie z językiem i merytoryką, słabo obsługuje znaczniki.
“We are planning to evaluate ROI (cost and TAT decrease) for AVT with one of our customers, we’ll keep you posted 😊”
Prezentacja pochodzi z tegorocznej konferencji MT Summit 2020-2021.
Intento jest tym graczem na rynku MT, który nie koncentruje się na budowaniu własnych silników, tylko na dostarczaniu narzędzi ułatwiających używanie MT różnich firm. Ostatnio zaproponowali rozwiązanie wspomagające tłumaczenie maszynowe stringów w notacji ICU, o których newsletter Intento wspomina w sposób lekko niepokojący:
Considering that professional translators will find themselves confused by the ICU format, this is a massive step towards raising the level of your MT past even the gold standard of human translation.
Niepokoi nie tyle sugestia, że MT może być lepsze od tłumacza, co implikacja, że teksty bardzo nieprzyjazne do tłumaczenia profesjonalnego mogą być zrobione przez maszynę równie dobrze, bo tłumacz i tak się w nich nie połapie…
Cukier jest w puszcze po herbacie z napisem “sól”.
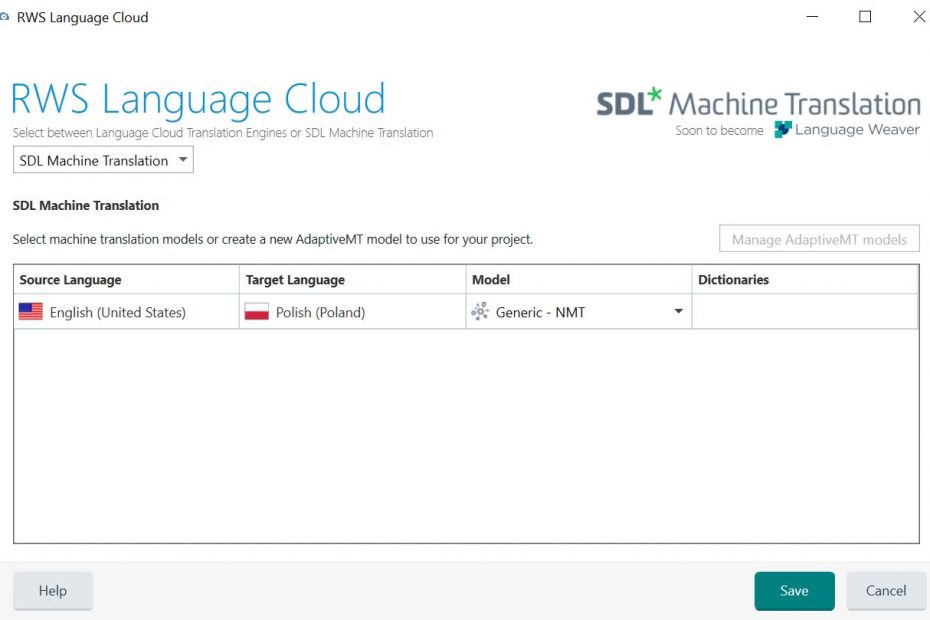
Nowy silnik NMT, RWS Language Weaver, jest już dostępny w Tradosie – dla niepoznaki wciąż pod opcją SDL Language Cloud 🙂 Użytkownicy Studio mogą go wypróbować bezpłatnie – z desktopowej wersji Tradosa 2021 lub 2019, z Trados Live lub bezpośrednio z przeglądarki. Do skorzystania z MT trzeba zalogować się na konto (zwane SDL ID lub SDL Language Cloud).
Jeśli macie już ulubioną wtyczkę do MT, na przykład DeepL czy Google, to można testowo podłączyć na jakiś czas Language Weavera jako drugi silnik.
Dostosowanie MT za pomocą glosariusza jest dostępne tylko w wersji płatnej, a trening na własnych pamięciach – w wersji Enterprise.
Czego można spodziewać się po MT dotrenowanym pamięcią z dziedziny, w której pracujemy? A na ile MT może zaadaptować się do poprawek, jakie wprowadzamy poprawiając jego kolejne podpowiedzi?
Eksperyment z adaptującym się narzędziem do tłumaczenia maszynowego ModernMT został przeprowadzony przez Anonimową Tłumaczkę na platformie SDL Trados Studio 2017 w trzech fazach z wykorzystaniem tzw. tekstu „miękkiego” z obszaru nauk humanistycznych, w tłumaczeniu z języka polskiego na angielski:
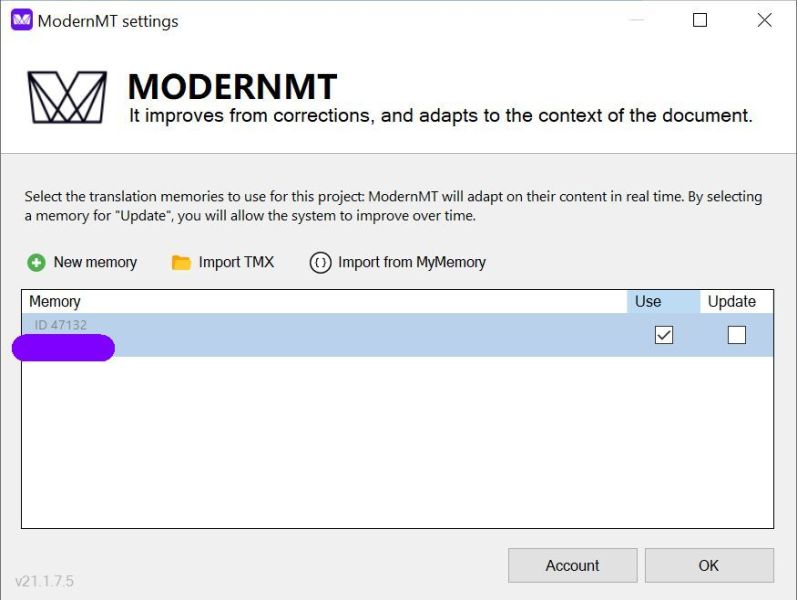
Faza 0 (ok. 18 tys. znaków ze spacjami) – podpięty silnik ModernMT bez żadnych dodatkowych zasobów.
Faza 1 (ok. 22 tys. znaków ze spacjami) – podpięty silnik ModernMT z pamięcią bazującą na wcześniej przetłumaczonych tekstach dotyczących tej samej tematyki (ok. 500 tys. znaków ze spacjami), ustawioną do wykorzystania przez silnik MT, lecz bez aktualizacji.
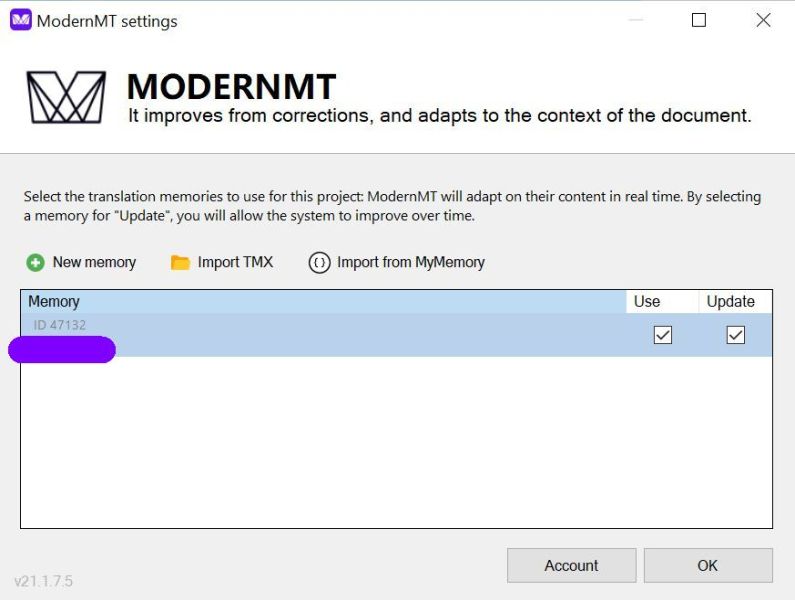
Faza 2 (ok. 60 tys. znaków ze spacjami) – podpięty silnik ModernMT z tą samą pamięcią, ustawioną do wykorzystania oraz aktualizacji przez silnik MT.
Faza 1 – silnik MT korzysta z pamięci
\W fazie 1 w stosunku do fazy 0 nastąpiła odczuwalna poprawa w zakresie doboru słownictwa. Klient miał określone wymagania co do nazewnictwa – faza 0 wymagała ze strony Tłumaczki w większości przypadków ręcznego wprowadzania poprawek, natomiast w fazie 1 silnik ModernMT dobierał właściwe określenia w ok. połowie przypadków.
Przykład terminologiczny (Faza 1):
Słowem często używanym w źródle było słowo panna. W fazie 0 silnik ModernMT tłumaczył to słowo na różne sposoby, przykładowo jako virgin czy maid, co Tłumaczka wielokrotnie zmieniała na maiden. Po zastosowaniu pamięci, w której występowała wyłącznie forma maiden, silnik ModernMT przeszedł na wersję maiden.
Przykład stylistyczny (Faza 1):
Ze społecznego punktu widzenia sprawa nie była jednak tak prosta i oczywista, zważywszy na stosunkowo późny wiek zawierania małżeństw.
MT: From a social point of view, however, the issue was not so simple and obvious, given the relatively late age of entering into marriages.
W fazie 0 tłumaczenie maszynowe bardzo często używanego w tekście źródłowym wyrażenia zawrzeć małżeństwo brzmiało conclude a marriage, co Tłumaczka wielokrotnie zmieniała na enter into a marriage/enter into marriages. Po zastosowaniu pamięci, w której występowała wyłącznie forma enter into a marriage/enter into marriages, silnik ModernMT zaczął dość konsekwentnie (aczkolwiek mniej konsekwentnie niż w fazie 2) używać sformułowania z enter into.
Faza 2 – silnik MT korzysta z pamięci i z poprawek
Poprawa stała się jeszcze bardziej dostrzegalna w fazie 2 – terminologia była właściwie dobierana w ponad połowie przypadków, poza tym tłumaczenie maszynowe zaczęło naśladować styl Tłumaczki, co przejawiało się w używaniu charakterystycznych wyrażeń, które Tłumaczka wcześniej wprowadzała ręcznie.
Przykład terminologiczny (Faza 2):
Jednym z wyrazów używanych w źródle było słowo testator, początkowo tłumaczone przez ModernMT jako tester (poprawne tłumaczenie to również testator). Po kilku (ok. 10) poprawkach ręcznych silnik ModernMT przeszedł na wersję tetator, a następnie już na poprawne tłumaczenie testator.
Przykład stylistyczny (Faza 2):
Charakter bazy nie pozwala jednak jednoznacznie określić ich udziału…
MT: However, the nature of the database does not make it possible to clearly determine their share…
Poprzednie tłumaczenie maszynowe nie pozwala brzmiało: does not allow for, co było przez Tłumaczkę konsekwentnie zmieniane na does not make it possible to. W fazie 2 silnik ModernMT „podchwycił” sformułowanie does not make it possible to.
Tłumaczenie maszynowe wymagało stałego nadzoru, ponieważ można było zaobserwować ewidentne „spadki formy” i powrót do poprawianych przez Tłumaczkę wersji. Można jednak z dużą dozą pewności stwierdzić, że w fazie 2 liczba zastosowanych form poprawnych wśród obserwowanych sformułowań przeważała nad liczbą form niepoprawnych.
Tłumaczka nie odnotowała zauważalnego zwiększenia szybkości tłumaczenia w kolejnych fazach (prawdopodobnie ze względu na charakter tekstu szybkość tłumaczenia utrzymywała się na stałym poziomie 9 tys. znaków ze spacjami na godzinę), jednak szczególnie w fazie 2 dało się dostrzec zwiększoną „lekkość” tłumaczenia – praca nad nim stała się wyraźnie łatwiejsza.
Warto zwrócić uwagę, że stała szybkość tłumaczenia odnosi się do wcześniejszej pracy z nietrenowanym MT (ModernMT, wcześniej DeepL), a nie do pracy bez żadnych podpowiedzi z MT.
Pojawił się kolejny raport opisujący użycie przez Pangeanic korpusu tematycznego dostarczonego przez TAUS, aby uzyskać lepsze MT na tematy COVID-owe. Dla 5 par językowych odnotowano średnią poprawę jakości o 22% wg miary automatycznej BLEU – natomiast wyniki są rozrzucone w ciekawy sposób:
najlepiej wypada para angielski > rosyjski (50% poprawy), najgorzej – angielski > polski (8%), choć można by się spodziewać, że dwie tradycjnie trudne pary angielski > słowiański osiągną podobny wynik;
o ile para angielski > chiński notuje wysoką poprawę (26%), o tyle angielski > hiszpański – niewielką (9%), więc z kolei dwie “łatwe” pary wypadły ze sporym rozrzutem.
Można spekulować, że takie nieoczywiste wyniki są związane z różną jakością bazowych korpusów dla poszczególnych par językowych.
Raport zawiera też analizę przykładów tłumaczenia i wskazuje, w jaki sposób korpus tematyczny poprawia terminologię i ogólną jakość tłumaczenia na temat COVID-19. Brak natomiast większej analizy nowego MT tematycznego w ocenie tłumaczy-postedytorów lub odbiorców bezpośrednich, czy też danych o wydajności postedycji.
Strona używa plików cookie. Zakładam, że Ci to nie przeszkadza, ale zawsze możesz zmienić ustawienia.OK
Prywatność i ciastka
Ogólne zasady ochrony prywatności
Ta strona wykorzystuje pliki cookie. Pliki cookie niezbędne do działania strony są przechowywane w przeglądarce użytkownika i konieczne, aby strona działała prawidłowo. Wykorzystujemy też pliki cookie stron trzecich, które pomagają nam analizować sposób, w jaki użytkownicy korzystają ze strony. Takie pliki cookie są zapisywane w przeglądarce użytkownika tyko za jego zgodą. Użytkownik może z nich zrezygnować, ale może to wpłynąć na funkcjonalność strony.
Pliki cookie, które nie są niezbędne do działania strony i służą do gromadzenia danych osobowych przez funkcje analityki lub inne osadzone treści. Użytkownik strony musi zgodzić się na ich stosowanie