Glosariusz DeepL w CAT-ach
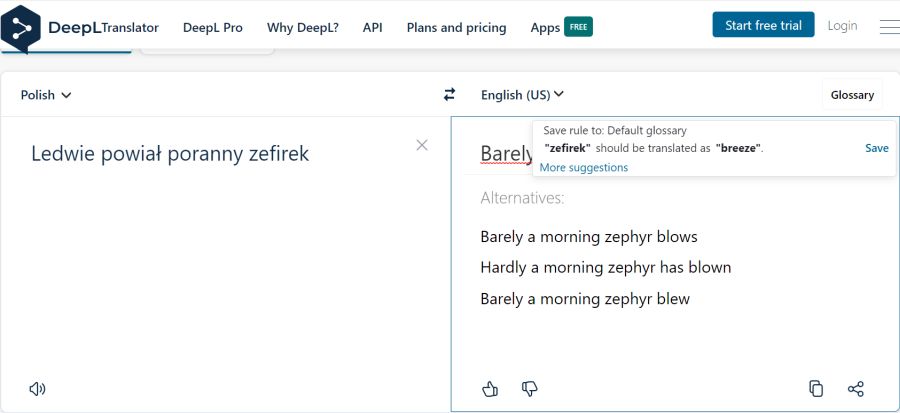
DeepL: robi funkcję glosariusza do MT prostą jak irlandzka dzida bojowa
memoQ: robi obsługę glosariusza DeepL równie prostą, wczytujesz słowniczek z pliku CSV i jedziesz
RWS: robi obsługę glosariusza DeepL w Tradosie tak skomplikowaną, że wymaga dokumentacji, a i tak w pierwszej chwili trudno się w niej połapać, sądząc po reakcjach na forum (oraz wciąż ma parę bugów, które zgłosiłam w beta testach, ale nie powiem które to – niech każdy ma swój kawałek rozrywki ![]()
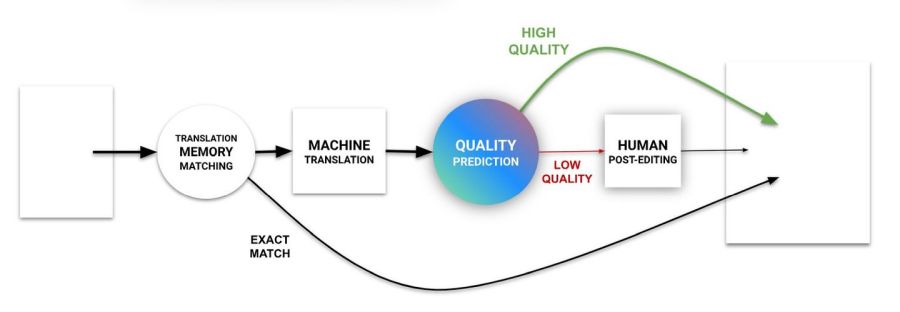
W każdym razie: glosariusz do DeepLa w Tradosie już jest, w podtłumaczaniu działa jak złoto, odmienia przez przypadki itd.
Uwaga 1: tylko do (od?) Tradosa 2022.
Uwaga 2: glosariusz na stronie DeepL i glosariusz do CAT-a to dwa różne glosariusze, tak to DeepL zorganizował. Można eksportować i importować, formatem wymiany jest podstawowy CSV.
Instalacja stąd: https://appstore.rws.com/Plugin/24
Dokumentacja tu: https://community.rws.com/…/deepl-translation-provider
A z burzliwą historią powstawania można się zapoznać (lub coś w niej od siebie pomarudzić) tutaj: https://community.rws.com/…/deepl-plugin…/159430